Mikhail P. Ponomarenko, Anatoly S. Frolov, Julia V. Ponomarenko, Olga A. Podkolodnaya, Denis V. Vorobyev, Nikolay A. Kolchanov
Laboratory of Theoretical Genetics, Institute of Cytology and Genetics, Novosibirsk, 630090, Russia; pon@bionet.nsc.ru
and
G. Christian Overton, Center for Bioinformatics, University of Pennsylvania, Philadelphia, PA 19104-6145, USA; coverton@cbil.humgen.upenn.edu
The Central Limit Theorem-based approach for increasing the accuracy of the recognition of a given functional site in an arbitrary DNA sequence has been suggested. It implies the averaging of a huge number of partial recognitions of the site analyzed into the ōmean recognitionö of this site. To design this huge number of the partial recognition procedures within the framework of the consensus and frequency matrix formalisms, a great number of novel computable oligonucleotide alphabets have been used. On this basis, the activated and intelligent database SAMPLES has been created; it contains the sets of DNA functional sites identified experimentally, multiply aligned, and processed to be recognized in an arbitrary DNA sequence by their consensuses and frequency matrixes. The novel opprotunities of SAMPLES was demonstrated using GATA-1, C/EBP and NF-1 transcription factor binding sites. All the control results are shown and discussed. SAMPLES is available at http://wwwmgs.bionet.nsc.ru/
Keywords: pattern recognition, activated database, Central Limit Theorem, human genome annotation, program generation, I and II type error rates.
Recognition of functional sites in nucleotide sequences is one of the key episodes in genomic DNA annotation [1]. A huge number of methods have been so far developed to address the problem (for review, see [2]). The most widely used are the consensus and matrix methods [3-7] based on the evolutionary conservative nucleotides of functional sites. Recent evaluations of the accuracies of these methods for annotation of long genomic DNA fragments [8, 9] have, on the one hand, demonstrated a drastic progress in recognition of unknown genes and regulatory regions encoded in the genomic DNA and, on the other hand, the demand for considerable increase in the accuracy of the recognizing procedures for the functional sites in the actual application of genomic DNA annotation [8, 9].
Basing on the above bulk of intelligence, we are suggesting a systemic approach aiding the increase in the accuracy of a given functional site recognition in the course of genomic DNA annotation. It implies the averaging of a huge number of partial recognitions of
the site analyzed into the ōmean recognitionö of this site. The consensuses and frequency matrixes in 20 novel computable
alphabets have been used, and the activated database SAMPLES on the DNA site sequences identified, multiply aligned, and transformed into the C-code recognition programs has been created. The procedure was tested using the GATA-1, C/EBP and NF-1 transcription factor binding sites. SAMPLES is available at http://wwwmgs.bionet.nsc.ru/.
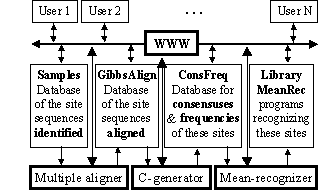
Figure 1. The scheme of the database SAMPLES.
The scheme of the system suggested is in the Fig.1. Its key module is the C-code generator for the computer programs recognizing a given functional site; initializing data for this module is experimentally identified and multiply aligned DNA sequences.
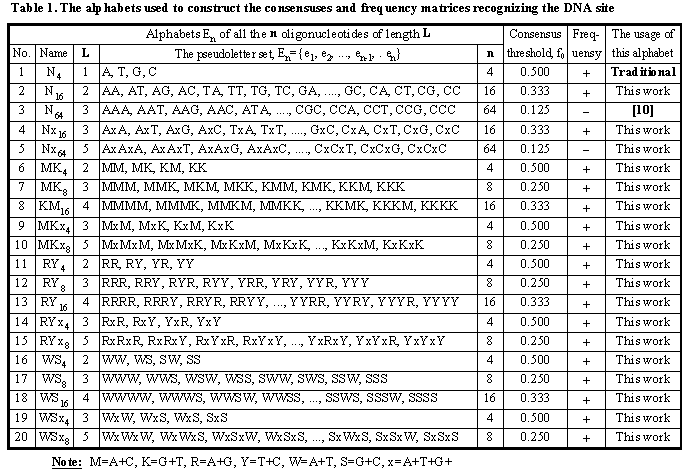
DNA is a linear molecule containing monomers A, T, G, and C. The site consensus is the set of the letters positioned with frequencies higher than the threshold f0.

Fig.2 exemplifies the simplest C-code of the programs recognizing the GATA-1 site by (a) its consensus, ōGATAAAGGö, and (b) its frequency matrix.
Fig. 2b, d demonstrate how the simplest C-code programs can be easily generalized for generating a huge number of (c) consensuses and (d) frequency matrices using the 20 alphabets listed in Table 1. Using the database GibbsAlign of the multiply aligned DNA sequences of a given functional site (Fig. 1), the system SAMPLES can generate all the possible consensuses and frequency matrices {fk} applicable to recognition of this site in an arbitrary sequence (1? k? K).
The simplest simultaneous usage of all these partial recognitions is averaging their values {fk(S)} over the region S of an arbitrary DNA sequence:
FK(S) = S k=1,K fk(S)/K. (1)
where the recognition values fk(S) are normalized as:
S n=1,N fk(Siten)/N = 1; (1a)
S n=1,N fk(Randn)/N =-1; (1b)
and the below decision rule is implemented:
IF {FK(S)>0}, THEN {S is ōthis siteö}. (1c).
By Central Limit Theorem, the mean recognition FK Eq.
(1) with high K is Gaussian-distributed and its variation K-1/2-fold
reduced. In contrast, the partial recognitions are often (a) discrete for consensuses and
(b) multiple modal for frequency matrices (Fig. 3). 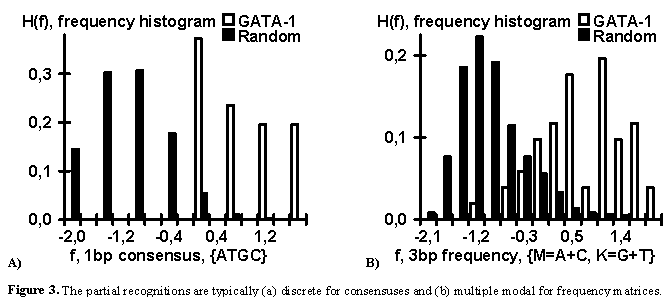
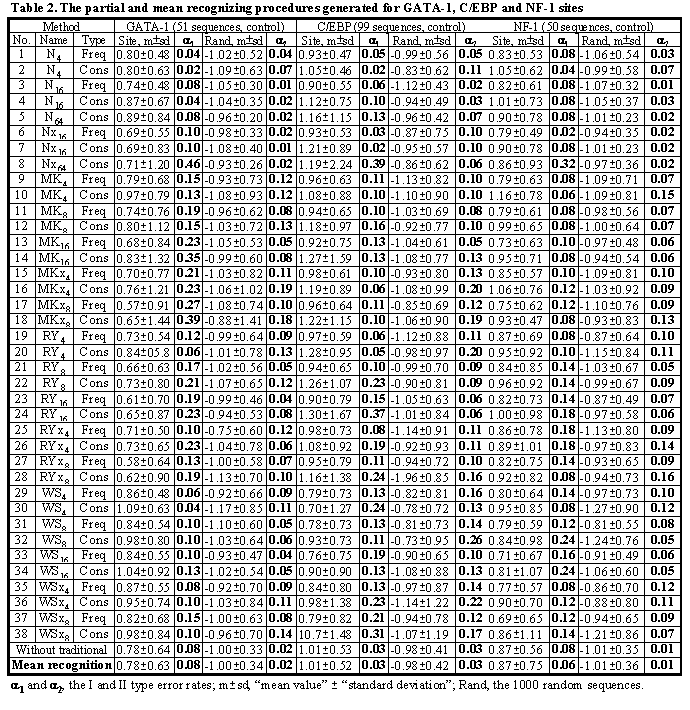
The mean recognition suggested has been used to process the experimentally identified and multiply aligned DNA sequences of GATA-1, C/EBP, and NF-1 transcription factor binding sites (the total number of sequences analyzed was 102, 62 and 99, respectively). All the data are available in the databases SAMPLES and GibbsAlign, http://wwwmgs.bionet.nsc.ru/ (Fig. 1).
Each of these three sequence sets was randomly divided into two non-overlapping 50%-subsets, training and control. In the training sets, all the possible consensuses and frequency matrices were identified to generate the programs recognizing these sites. Their C-codes are stored in the database ConsFreq and executable in MeanRec, http://wwwmgs.bionet.nsc.ru/, (see in Fig.1).
Using the control subsets and 1000 random DNA sequences, each of the partial recognition procedures was tested. The complete test results are shown in Table 2 (lines 1-38). Similarly, their mean recognitions have been tested (Table 2). For more detail on these control test results, see the database ConsFreq at http://wwwmgs.bionet.nsc.ru/.
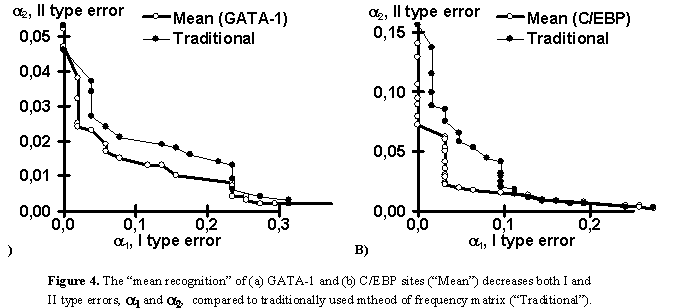
Note that the partial recognitions differ from one another in their means and standard deviations, I and II type error rates of both the site and random DNA sequences. Essentially, it is impossible to predict what partial recognition would be the best for an arbitrary site; in contrast, the mean-recognition appears the best for each of the three site tested. Fig. 4 illustrates that the mean recognition can decrease both the I and II type errors, a1 and a2, with respect to the frequency matrix. This is demonstrated for (a) GATA-1 and (b) C/EBP transcription factor binding sites.
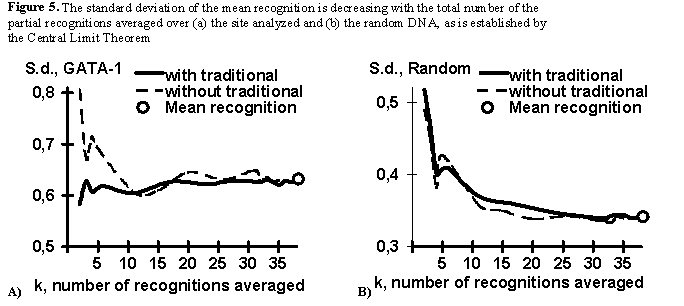
To investigate this phenomenon, we studied the alteration of the statistical properties of the standard deviation of the GATA-1 mean recognition FK, with the growth of the total number K of the GATA-1 averaged partial recognition procedures. In this test, for each value K, ten different combinations of the partial recognition procedures {fk} was randomly chosen and their standard deviations for 51 control sequences of the GATA-1 site and 1000 random DNA sequences were calculated and averaged. Two variants of this analysis were carried out: with and without the GATA-1 consensus and frequency matrix used traditionally for the GATA-1 recognition.
The results obtained are presented in Fig. 5 for (a) the GATA-1 control subset and (b) for the random DNA (bold line, when with traditional recognitions; broken line, without). In case of the GATA-1 sites (Fig. 5a), the standard deviation value is approximately constant at any K values when the traditional recognitions are used (Fig.5a, bold line). This means that the GATA-1 sequences analyzed have been optimized by their preliminary alignment to create these traditional recognition procedures [11]. When the traditional recognition procedures were not involved (Fig.5a, broken line), the standard deviation value is approximately K-1/2-fold decreasing with the K value (as is established by the Central Limit Theorem) until its alignment-dependent level reached. Essentially, the Central Limit Theorem-established decreases are for the random DNA sequences in both variants, with and without the traditional recognition procedures (Fig.5b). These results pinpoint that the mean recognition FK Eq. (1) suggested in this work is increasing the accuracy of a given functional site recognition through the K-1/2-fold decrease of the standard deviation of the non-site sequences which is responsible for the II type error, a2.
In this work, we introduce the idea of simultaneous involvement of as many procedures recognizing a functional site in an arbitrary DNA sequence as we can design. The simplest implementation of this idea is averaging the all partial recognizing procedures available. This has been named the ōmean recognitionö. Unexpectedly, the analysis of the mean recognition shows that its statistical properties are asymptotically described by the Central Limit Theorem. Essentially, this theorem establishes that the mean recognition FK should became Gaussian-distributed and its standard deviation K-1/2-fold decreased with the total number K of the partial recognitions averaged. We have observed this essential decrease (Fig. 5). This means that the mean recognition functioning should be predictable by the Central Limit Theorem even when all its partial recognitions will be heuristic with their unpredictable functioning. Thus, the mean recognition is the systemic approach increasing the accuracy of the functional site recognition for the genomic DNA annotation.
Further development of the mean recognition approach will focus on the increase in the total number K>>100 of the averaged partial recognitions {fk} through involvement of additional methods, such as Information Content, Perceptron, Neural Network, etc. Various weighting of the partial recognitions within the mean recognition will be also studied. Finally, it is interesting to implement the Central Limit Theorem to design the mean recognitions for increasing the accuracy of the coding potentials of exons, the non-coding potentials of introns, and the regulatory potentials of promoters [12-14]. All these will be performed within the framework of our Web-integrated system GeneExpress [15] available at the URL: http://wwwmgs.bionet.nsc.ru/.
We are grateful to Ms. Galina Chirikova for the help in translation. This work was granted by NIH 2-R01-RR04026-08A2; Russian Human Genome Project; Russian Foundation for Basic Research 97-04-49740, 96-04-50006, 97-07-90309, 98-07-90126; SB RAS IG-97N13 and Program for the Young Scientists Support.
REFERENCES
[1] Fickett, J.W. ōFinding genes by computer: the state of the art.ö Trends Genet., V. 12, 1996, pp. 316-320.
[2] Gelfand, M.S. ōPrediction of function in DNA sequence analysis.ö J. Comput. Biol., V. 2, 1995, pp. 87-115.
[3] Bucher, P. ōWeight matrix descriptions of four eukaryotic RNA polymerase II promoter elements derived from 502 unrelated promoter sequences.ö J. Mol. Biol., V. 212, 1990, pp. 563-578.
[4] Karlin, S. and Brendel, V. ōChance and statistical significance in protein and DNA sequence analysis.ö Science, V. 257, 1992, pp. 39-49.
[5] Quandt, K., Frech, K., et al. ōMatInd and MatInspector - New fast and sensitive tools for detection of consensus matches in nucleotide sequence data.ö Nucl. Acids Res., V. 23, 1995, pp 4878-4884.
[6] Uberbacher, E.C., Xu, Y., and Mural, R.J. ōDiscovering and understanding genes in human DNA sequence using GRAIL.ö Methods Enzymol., V. 266, 1996, pp. 259-281.
[7] Chen, Q.K., Hertz, G.Z., and Stormo, G.D. ōPromFD 1.0: a computer program that predicts eukaryotic pol II promoters using strings and IMD matrices.ö Comput. Appl. Biosci., V. 13, 1997, pp. 29-35.
[8] Fickett, J.W. and Hatzigeorgiou, A.G. ōEukaryotic promoter recognition.ö Genome Res., V. 7, 1997, pp. 861-878.
[9] Burset, M. and Guigo, R. ōEvaluation of gene structure prediction programs.ö Genomics, V. 34, 1996, pp. 353-367.
[10] Kondrakhin, Yu.V., Shamin, V.V., and Kolchanov, N.A. ōConstruction of a generalized consensus matrix for recognition of vertebrate pre-mRNA 3'-terminal processing sitesö. Comput. Appl. Biosci., V. 10, 1994, pp. 597-603.
[11] Lawrence, C. ōToward the unification of sequence and structural data for identification of structural and functional constraints.ö Comput. Chem., V. 18, 1994, pp. 255-258.
[12] Solovyev, V.V., Salamov, A.A., and Lawrence, C.B. ōPredicting internal exons by oligonucleotide composition and discriminant analysis of spliceable open reading frames.ö Nucl. Acids Res., V. 22, 1994, pp. 5156-5163.
[13] Guigo, R. and Fickett, J.W. ōDistinctive sequence features in protein coding genic non-coding, and intergenic human DNA.ö J. Mol. Biol., V. 253, 1995, pp. 51-60.
[14] Kondrakhin, Y.V., Kel, A.E., Kolchanov, N.A., Romashchenko, A.G., and Milanesi, L. ōEukaryotic promoter recognition by binding sites for transcription factors.ö Comput. Appl. Biosci., V. 11, 1995, pp. 477-488.
[15] Kolchanov N. A., Ponomarenko M. P., et al., ōGeneExpress: a computer system for description, analysis, and recognition of regulatory sequences of the eukaryotic genomeö. ISMB, V. 6, 1998, (accepted).