Предложено компьютерное представление знаний об активности ДНК и РНК в виде кодов программ для предсказания неизвестной активности по известным последовательностям этих биополимеров. На этой основе создан метод автоматической генерации таких знаний по примерам последовательностей ДНК (РНК) с известной активности. Построена база знаний по основным типам активности молекул ДНК и РНК, которая доступна по <http://sgi.sscc.ru/>.
ДНК (РНК) являются полимерами большой длины, состоящими из мономеров-нуклеотидов A, T (U), G и C. Функциональная активность этих молекул определяется короткими участками их взаимодействия с белками и низкомолекулярными веществами [1]. Для тысяч таких участков определены нуклеотидные последовательности и величины активности. Причем разные участки однотипной активности различаются по ее величине на несколько порядков.
Предсказание неизвестной активности ДНК (РНК) по ее известной последовательности становиться все более актуальным: именно различия активности регулируют и координируют работу генов в жизнедеятельности организмов. Предсказание активности ДНК (РНК) является также важным для генно-инженерного конструирования искусственных систем производства биологически-ценных продуктов генов. Внимание к предсказанию активности ДНК привлекает и задача оценка риска ее повреждения мутагенами, приводящими к патологиям организмов.
Миллиган [2] был первым, кто стал предсказывать активность промотора E. coli прорционально сходству его последовательности с последовательностями всех известных промоторов. Стормо [3, 4] применил регрессионную оценки порциального вклада каждого нуклеотида в каждой позиции ДНК (РНК) в ее активность. Берг и ван Хиппель [5] обобщили оба эти подхода в статистическую механику ДНК-белковых взаимодействий. Джонсон [6] ввел нейронные сети для предсказания силы промоторов E. coli. С помощью нейронных сетей были созданы методы предсказания сродства ДНК к белкам INR и TBP [7]. В целом, несмотря на тысячи известных участков ДНК и РНК с установленными активностями, лишь для некоторых из них была показана возможность предсказания активности несколькими частными методами.
В данной работе вводится компьютерное представление знаний об активности ДНК (РНК) в виде программ предсказания неизвестной активности по известным последовательностям этих биополимеров. На этой основе создан метод автоматической генерации таких знаний по примерам последовательностей ДНК (РНК) с известной активности. Построена база знаний по основным типам активности молекул ДНК и РНК, которая доступна по <http://sgi.sscc.ru/>.
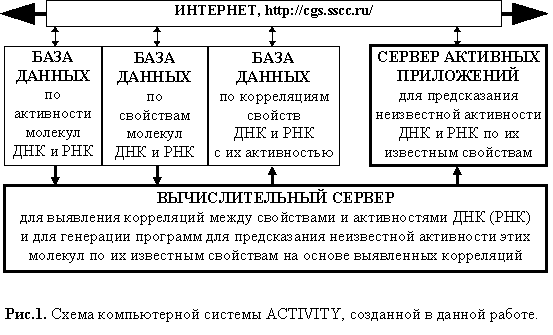
Схема базы знаний Activity по функциональной активности ДНК и РНК дана на рис. 1. ACTIVITY имеет три базы данных: 1) по активности ДНК и РНК; (2) по свойствам ДНК и РНК; (3) по корреляциям между свойствами ДНК и РНК с их активностью. Они составляют так называемый "сервер баз данных". Соответственно, ACTIVITY имеет так называемый "сервер активных приложений" с кодами программ для предсказания неизвестной активности ДНК и РНК по известным свойствам этих молекул. Наконец, ACTIVITY имеет "вычислительный сервер", автоматически выявляющий по известным примерам активности ДНК и РНК участки этих молекул, на которых средние значения их конформационных, физико-химических и статистических свойств коррелируют с известными величинами активности, и генерирует по этим корреляциям соответствующие коды предсказывающих программ.
Ключевым в ACTIVITY является вычислительный сервер (рис.1). При описании метода его работы будут вводиться необходимые обозначения. Пусть S=s1...si...sL последовательность ДНК (РНК) длиной L нуклеотидов sI {A, T(U), G, C} с известной величиной F ее активности. Пары "последовательность-активность", (S-> F), хранятся в базе данных по активности ДНК и РНК, формат которой совместимой с языком управления данными SRS [8]. В качестве примера на рис.2 показаны пары (S->F) для силы промоторов E. coli [6]. Поле "MN" содержит название активности; "AU" - единицы измерения, "SC" - обозначение варианта нуклеотидной последовательности, "SA" - величину активности. Например, вариант ДНК с именем "LS1" имеет последовательность "TCCGT...AGGAAT" и сила промотора -log[Pbla]=2.143, а вариант ДНК "con/anti" имеет другую последовательность и силу -log[Pbla]=0.255 логарифмических единиц. Такое 100-кратное различие абсолютных значений силы промоторов не оставляет сомнений в том, что зависит от нуклеотидной последовательности молекулы ДНК.
Отличительной особенностью метода ACTIVITY является промежуточное преобразование нуклеотидных последовательностей в количественные характеристики. Такой характеристикой является взвешенная концентрация подпоследовательностей Z=z1...zj...zm длины m<<L:
![]() , (1)
, (1)
![]() .
.
здесь: zjI {A, T(U), G, C, W=A/T(U), R=A/G, M=A/C, K=T(U)/G, Y=T(U)/C, S=G/C, B=T(U)/G/C, V=A/G/C, H=A/T(U)/C, D=A/T(U)/G, N=A/T(U)/G/C}; w(i) - весовая функция, построенная по правилу: "чем важнее позиция i для анализируемой активности ДНК (РНК), тем больше w(i). В Activity используется 180 весовых функций w(i) с один минимумом или максимумом в пределах последовательности ДНК (РНК) с разными положением и шириной ее экстремума. На рис.3 показаны примеры функций w(i) с максимумом в правой половине (а), в центре (б) и на концах (в) последовательности. Комбинирование всех возможных подпоследовательностей Z длины m от 1 до 4 со всеми этими 180 функциями w(i) дает » 107 характеристик XZ,m,w.
Другим типом "контекстных" характеристик является среднее значение определенного свойства ДНК (РНК) на участке [a; b] последовательности S длины L (здесь: 1 a <= b-1<= L-1):
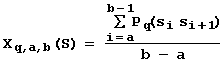 , (2)
, (2)
здесь: Pq - q-ое свойство из базы данных по свойствам ДНК и РНК (1<= q<= Q). На рис.4 в качестве примера таких свойств и их представления в ACTIVITY показан угол Direction [9]. Для L=100 и Q=100 комбинаторных перебор дает » 106 разных вариантов характеристик Xq,a,b.
Для исходных данных "последовательность-активность" (Sn-> Fn) является неизвестным какие из » 107 характеристик XZ,m,w(Sn) и » 106 характеристик Xq,a,b(Sn) коррелируют с активностью (Fn). Поэтому метод ACTIVITY состоит в полном комбинаторном переборе всех » 107 характеристик X#,$,@ и проверке наличия таких корреляций независимо для каждой из этих характеристик (здесь: {#,$,@}={Z,m,w} для формулы (1) и {#,$,@}={q,a,b} для формулы (2)).
При фиксированных значениях индексов {#,$,@} для каждой последовательности Sn вычисляется значение характеристики X#,$,@(Sn). Получаются пары величин{X#,$,@(Sn)-> Fn}. Чтобы по известным X#,$,@ можно было предсказывать неизвестные F, пары {X#,$,@(Sn)-> Fn} должны отвечать требованиям регрессионного анализа. Для их проверки строится регрессия:
![]() ; (3)
; (3)
здесь: f0 и f1 - регрессионные коэффициенты, вычисляемые по парам чисел {X#,$,@(Sn)-> Fn}.
С ее помощью пары {X#,$,@(Sn)-> Fn} преобразуются в пары "предсказанная-известная" активность, {F#,$,@(Sn)-> Fn}. Для них проверяется 11 требований регрессионного анализа: линейной, знаковой и двух ранговых корреляций; равенства средних значений и плотностей распределения, независимость, несмещенность и нормальность распределения отклонений {D n=F#,$,@(Sn)-Fn} между предсказанными и известными активностями. Для уменьшения зависимости от исходных данных каждое требование проверяется на двух неперекрывающихся половинах данных: на 50% больших и на 50% меньших известных активностях. При этом с помощью соответствующего критерия оценивается значимость a rt выполнения r-ое требование (1<= r<= 11) на t-ой половине данных (1<= t<= 2). Эта значимости a rt преобразуются, в терминах нечетких множеств Задэ [10], в оценку urt(Х#$@-> F) "полезности X#$@ для предсказания F":
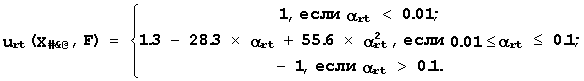 (4)
(4)
Характеристика Х#$@ получает высшую оценку urt=1, когда пары {F#,$,@(Sn)-> Fn} на t-ой половине данных отвечают r-ому требованию при a rt<0.01; низшую оценку urt=-1, когда это не выполнено (a rt>0.1); промежуточную -1<= urt<= 1 при 0.01<= a rt<= 0.1. Всего характеристика X#$@ получает 22 частные оценки ее полезности для предсказания активности F.В терминах теории принятия решений [11], усреднение частных оценок полезности дает ее интегральную оценку:
![]() . (5)
. (5)
Если большинство требований регрессионного анализа выполнено, то характеристика Х#$@ получает положительную оценку ее полезность U(Х#$@, F)>0, которая тем большее, чем большее требований выполнено. Верхнюю оценку вероятности получить U(Х#$@, F)>0 по случайным причинам можно оценить с помощью биномиального распределения:
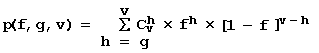 , (6)
, (6)
здесь: f - частота случайного выполнения характеристикой X#$@ проверяемого требования, v - число требований, g - число выполненных требований. При v=22, g=11 и f=0.01 получается p<10-16. Поскольку проверяется » 107 характеристик Х#$@, то вероятность случайно найти одну из них с U(X#$@, F)>0 не превышает 107<= 10-16=10-9. Поэтому каждая U(X#$@, F)>0 указывает характеристику X#$@, значимую для предсказания активности F при p<10-9.
После выявления всех характеристик X#$@ с U(X#$@, F)>0 из их числа выбираются самые полезные линейно-независимые {Xk}, с помощью которых строится множественная регрессия:
![]() . (7)
. (7)
Выявленные характеристики {Xk}, их полезности {U(Xk,F)} и сгенерированные для формул (1, 2 и 7) коды программ заносятся в базу данных по корреляциям между свойствами ДНК и РНК и их активностью, а исполняемые программы заносятся на сервер активных приложений для предсказания неизвестных активностей ДНК и РНК по их известным свойствам (рис.1).
В качестве примера работы ACTIVITY рассмотрим анализ силы промоторов E. coli (рис.2). Исходные данные содержали 9 из 27 известных промоторов (L/N25DSR, D/E20, L, N25, G25, J5, N25/lac, con и con/anti), тогда как остальные 18 промоторов были контрольными. Для этих исходных набольщую полезность U=0.59 имела взвешенная концентрация тринуклеотидов ASM с весовой функцией w(i), показанной на рис.3а. Максимум этой функции вблизи старта транскрипции (позиция 1) согласуется c известной наибольшей важностью этого старта для силы промоторов E. coli [6]. Второй по величине полезности U=0.50 был средний угол Direction на участке [-4, 16] вокруг старта транскрипции. На рис.5а показана линейная корреляция между взвешенной концентрации ASM и силой -log[Pbla] на контрольных данных, на рис.5б показана такая корреляция для среднего угла Direction. Обе эти корреляции являются достоверными: первая r=0.86 с a <10-3, вторая r=0.71 с a <10-2. На рис.6 показан сгенерированный С-код программы, предсказывающей силу промотора E. coli по взвешенной концентрации тринуклеотидов ASM и среднему углу Direction. На рис.5в показана достоверная корреляция между предсказанной и известной силой 27 промоторов E. coli (r=0.91, a <10-6).
С помощью ACTIVITY были исследованы также ряд других типов активности ДНК и РНК. Примеры полученных при этом результатов показаны в Таблице и на рис.7. Для сродства синтетических ДНК к ТВР-белку [12] было установлено, что оно определяется взвешенными концентрациями динуклеотидов TV в центре ДНК (рис 3б) и WR на ее концах (рис. 3в). Коэффициенты их линейной корреляции с ТВР/ДНК-сродством равны 0.73 и 0.76 (a <0.01). Сгенерированная на их основе программ предсказания ТВР/ДНК-сродства дала достоверную корреляцию между его предсказанными и известными величинами (рис.7а: r=0.77, a <0.01). На рис.7б показано предсказание ТВР/ДНК-сродства, усредненное по всем известным промоторам эукариот. Можно видеть, что ТВР/ДНК-сродство имеет пик в позиции -31 промоторов, которая является общеизвестным оптимальным участком связывания ТВР-белка с промоторной ДНК.
Для сродства синтетических ДНК к USF-белком [13] значимыми оказались глубина минорного желобка depth (r=-0.78, a <10-3) и угол закрученности twist (r=-0.86, a <10-4) спирали ДНК. Обе характеристики позволяют достоверно предсказывать сродство USF/ДНК (рис.7в).
Взвешенная концентрация тетранулеотида VUKK в районе 3’-концевого хвоста пре-мРНК была самой значимой для выхода зрелой мРНК вируса SV40 (рис. 7г: r=0.88, a <10-4). Этот тетрануклеотид является G/U-богатым (V={A,C,G}, K={U,G}), что согласуется с названием "G/U-богатый район” функционального сигнала в районе 3’-концевого хвоста пре-мРНК [14].
С помощью ACTIVITY установлено, что частота мутаций, вызванных 2-аминопурином [15] определяется температурой плавления ДНК в точке такой мутации (рис.7д: r=0.90, a <10-5).
Все эти результаты свидетельствуют о возможности применения предложенного подхода к широкому кругу типов активности ДНК и РНК. При этом наш подход имеет ряд ограничений. Прежде всего, применение формул (3-6) требует не менее 6 последовательностей ДНК (РНК) с известной активностью. Кроме того, выявленные закономерности являются значимыми только в условиях того эксперимента, результаты которого были исходными данными для ACTIVITY.
Работа была поддержана грантом ИГ СО РАН-97N13 Интеграционной Программы СО РАН.
ЛИТЕРАТУРА
1. Neidle S. DNA structure and recognition. Oxford: IRL Press, 1994. 108 P.
2. Mulligan M.E., et al. // NAR. 1984. V. 12. P. 789-800.
3. Stormo G.D., Schneider T.D., Gold L. // NAR. 1986. V. 14. P. 6661 6679.
4. Barrick D., et al. // NAR. 1994. V. 22. P. 1287-1295.
5. Berg O.G., von Hippel P.H. // J. Mol. Biol. 1988. V. 200. P. 709-723.
6. Jonsson J., et al. // NAR. 1993. V. 21. P. 733-739.
7. Kraus R.J., et al. // NAR. 1996. V. 24. P. 1531-1539.
8. Etzold T., Argos P. // CABIOS. 1993. V. 9. 49-57.
9. Shpigelman E.S., et al. // CABIOS. 1993. V. 9. P. 435-140.
10. Zadeh L.A. // Information and Control. 1965. V. 8, P. 338-353.
11. Fishburn P.C. Utility theory for decision making. N.Y.: Jonh Wiley & Sons, 1970.
12. Соколенко А.А. и др. // Мол.Биол. 1996. Т. 30. С. 279-285.
13. Bendall A.J., Molloy P.L. // NAR. 1994. V. 22. P. 2801-2810.
14. McDevitt M.A., et al. // EMBO J. 1986. V. 5. P. 2907-2913.
15. Coulondre C., et al. // Nature. 1978. V. 274. P. 775 780.
Таблица. Примеры знаний о функциональной активности ДНК и РНК из системы Activity
Участок молекулы ДНК или РНК |
Особенность |
Значимость |
|||||||
название [ссылка] |
позиция 1 |
n |
активность, F |
Xk | район |
свойство |
U |
r |
a |
промоторы E. coli |
старт тран- |
27 |
сила |
X1 | рис.3а |
[ASM] |
0.59 |
0.86 |
10-2 |
(ДНК) |
скрипции |
промотора |
X2 | -4; 16 |
Direction |
0.50 |
0.71 |
10-2 |
|
[6] |
(ед. -log[Pbla]) |
F=0.3+0.6<= X1+0.0008<= X2 | 0.91 |
10-4 |
|||||
синтетические ДНК |
первый |
19 |
сродство |
X1 | рис.3б |
[TV]) |
0.35 |
0,73 |
10-2 |
(ТАТА-бокс) |
нуклеотид |
TBP/ДНК |
X2 | рис.3в |
[WR] |
0.41 |
0,76 |
10-2 |
|
[12] |
F=14.5+2.5<= X1+0.9<= X2 | 0,77 |
10-2 |
||||||
синтетические ДНК |
первый |
14 |
сродство |
X1 | 11, 15 |
depth |
0.22 |
-0.78 |
10-3 |
(USF-элемент) |
нуклеотид |
USF/ДНК |
X2 | 11; 20 |
twist |
0.23 |
-0.86 |
10-4 |
|
[13] |
F=170-16.3<= X1-0.7<= X2 | 0.91 |
10-5 |
||||||
3’концевой хвост |
точка |
16 |
выход |
X1 | рис.3а |
[VUKK] |
0.24 |
0,88 |
10-4 |
пре-мРНК SV40 [14] |
отрезания 3’хвоста |
зрелой мРНК |
F=-301.72+216.16<= X1 | 0,88 |
10-4 |
||||
мутации ДНК (мута- |
точка |
26 |
частота |
X1 | -1, 2 |
Тплав |
0,20 |
0,90 |
10-5 |
ген 2-аминопурин) [15] |
мутации C-> T |
мутаций |
F=-8.5568+0.1585<= X1 | 0,90 |
10-5 |
||||
Примечания: n - число вариантов молекул ДНК (РНК); Xk - выявленная характеристика для предсказания активности; F=F0+S k=1,K Fk<= Xk - множественная регрессия (7) для предсказания функциональной активности молекул ДНК (РНК) по этим характеристикам; рис.3 - весовые функции w(i) для взвешенных концентраций коротких подпоследовательностей (формула 1).
MN Escherichia coli promoter strength
AU Digital logarithmic scale, -log[Pbla]
SC LS1
TCCGTCTCGA CGGGTTGACA CAAAAGCCAC AAGGGGTTAT AATGAGCACA
TAAACTTGAG AGAGGAAT
SA 2.143
//
...........................................
SC con/anti
ATTCACCGTC GTTGTTGACA TTTTTAAGCT TGGCGGTTAT AATGGATTCA
TCCGGAATCC TCTTCCCG
SA 0.255
//
Рис.3. Представление информации о силе промоторов E. coli [6] в базе данных по функциональной активности молекул ДНК и РНК: название активности (MN), единицы ее измерения (AU), имя молекулы ДНК и ее последовательность (SC), величина активности (SA).
а) б)
б) в)
в)
Рис. 2. Примеры различных весовых функций w(i) с разными положениями их максимумов: (а) в правой половине анализируемой последовательности, (б) в е центре; (в) на ее концах
PN Direction, Eulerian angle
PM Averaged for X-ray structures known
PU degree
AA -154.0
AT 0.0
AG 2.0
AC 143.0
TA 0.0
TT 154.0
TG 64.0
TC -120.0
GA 120.0
GT -143.0
GG 57.0
GC 180.0
CA -64.0
CT -2.0
CG 0.0
CC -57.
Рис.4. Представление свойств ДНК и РНК в Activity (на примере угла Direction [9]).
а)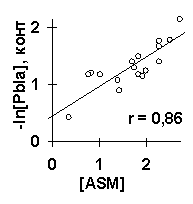 б)
б)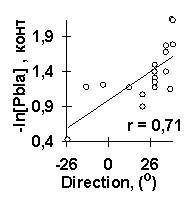 в)
в) 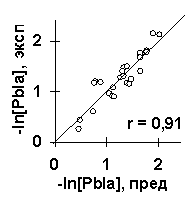
Рис.5. Пример применения ACTIVITY к исследованию силы промоторов E. coli: контрольная проверка взвешенной концентрации тринуклеотида ASM (a) и угла Direction (б); сравнение предсказанных и известных величин силы всех 27 промоторов E. coli (в).
MN Escherichia coli promoter strength
AU Digital logarithmic scale, -log[Pbla]
WW http://knight.bionet.nsc.ru/dbc/ec_pbla.htm
CF SEQUENCE-DEPENDENT STATISTICAL FEATURE
PV ASM
AB -49 19
UT 0.589
C-CODE
/* Promoter strength increases with ASM-content increase */
double WeightASM_for_EcPbla (char *s){
double X; char *seq; int i,k, SiteLength=68;
double Weigth5P0 [66]={
/* -49 -48 -47 -46 -45 -44 -43 -42 -41 -40*/
0.100,0.100,0.100,0.100,0.100,0.100,0.100,0.100,0.100,0.100,
...... ...... ...... ...... ...... ......
/* 11 12 13 14 15 16 */
0.525,0.356,0.207,0.143,0.103,0.100 };
seq=&s[0]; if(strlen(seq) < SiteLength+1)return(-1001.);
for (i=0, X=0.;i < SiteLength-2;i++) if(seq[i ]=='A')
...... ...... ...... ...... ...... ......
return(X);}
XX
CF SEQUENCE-DEPENDENT CONFORMATIONAL FEATURE
PV Direction
AB -5 15
UT 0.502
LC 0.710
XX
C-CODE
/* Promoter strength increases with Direction increase */
double Direction_for_EcPbla (char *s){
double X; char *seq; int i,k, SiteLength=21;
double DinucPar[16]={
/* AA AT AG AC TA TT TG TC */
-154., 0., 2., 143., 0., 154., 64.,-120.,
/* GA GT GG GC CA CT CG CC */
120.,-143., 57., 180., -64., -2., 0., -57. };
seq=&s[0]; if(strlen(seq) < SiteLength+1)return(-1001.);
for (i=0, X=0.;i < SiteLength-1;i++) {
switch (seq[i ]) { case 'A': k= 0; break;
...... ...... ...... ...... ...... ......
return (X/(double)(SiteLength-1));}
XX
CF PREDICTION ACTIVITY
LC 0.910
XX
C-CODE
/* Promoter strength prediction via ASM-content and Direction. */
double EcPbla_by_WeightASM_DirectionRegr (char *s){
extern double WeightASM_for_EcPbla (char *);
extern double Direction_for_EcPbla (char *);
double x1,x2; char *seq; int s1=0, s2=45, SiteLength=68;
seq=&s[ 0]; if(strlen(seq) < SiteLength+1)return(-1001.);
seq=&s[s1]; x1=WeightASM_for_EcPbla (seq); if(x1< -999.)return(x1);
seq=&s[s2]; x2=Direction_for_EcPbla (seq); if(x2< -999.)return(x2);
return (0.307547 + 0.576596*x1 + 0.000799*x2);}
//
Рис.6. Представление знаний о функциональной активности молекул ДНК и РНК в терминах С-кодов программ для предсказания такой активности (на примере силы промоторов E. coli).
а)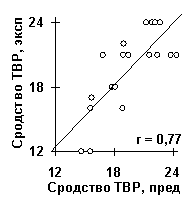 б)
б)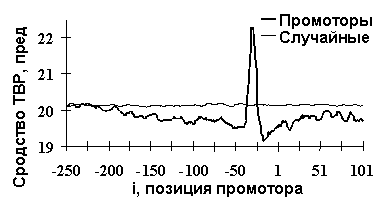
в)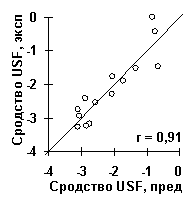 г)
г)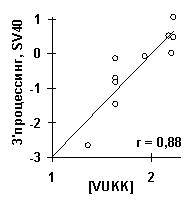 д)
д)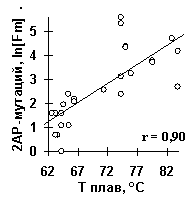
Рис.7. Примеры выявленных ACTIVITY знаний о функциональной активности ДНК и РНК: а) сродство синтетических ДНК к ТВР-белку [12]; б) предсказание ДНК/ТВР сродства, усредненное по всем известным промоторам, имеет пик в позиции -30, которая является общеизвестным оптимумом для связывания ТВР-белка с ДНК; в) сродство синтетических ДНК к USF-белку [13]; г) выход зрелой мРНК при 3’-концевом процессинге пре-мРНК вируса SV40 [14]; д) частота мутаций в гене lacI E.coli, вызванных мутагеном 2-аминопурин [15].

© 1997-99, IC&G SB RAS, Laboratory of Theoretical Genetics