
![]()
![]()
![]()
![]()
![]()
![]()
|
|
| [an error occurred while processing this directive] |
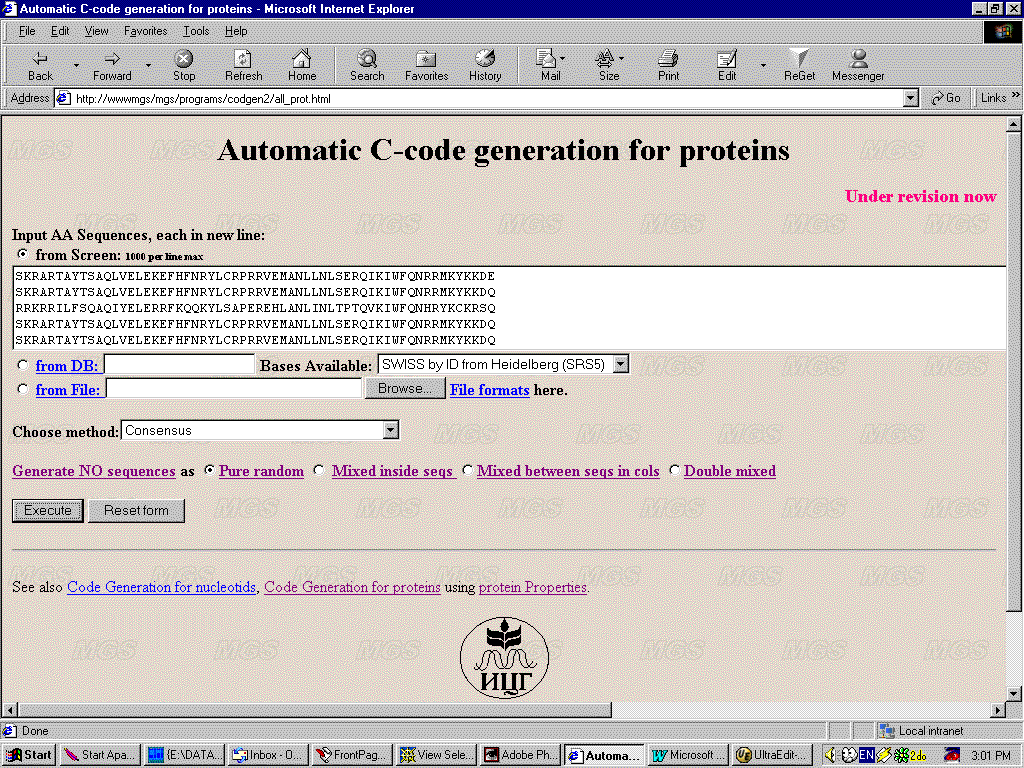
Brief manual on the Automatic C-code generation for proteinsEnter the Automatic C-code generation for proteins here. IntroductionThe Automatic C-code generation for proteins system generates a C-code for recognition of a given pattern in amino acid sequence. The current release uses the methods of consensus, weight matrix, perceptron algorithm, and the linear Fisher discriminant. Sets of positive and negative examples (training sets) are used as input data. To obtain the correct result, all the sequences in both sets should be aligned. The sequences representing given pattern are used as a positive example. The contents of the negative set are determined by the method applied and the task to be fulfilled. In any case, a set of random amino acid sequences can be used as a negative example. The sets obtained from the positive set through arbitrary rearrangement of the amino acid residues can be used as a negative set in case of weight matrix, linear Fisher discriminant, and perceptron algorithm. For the two last methods, the negative set can be additionally formed of the sequences of another site. The only condition for the sequences of the negative set is that they do not belong to the positive set. The result of these program operation is other C codes that recognize the regions in question in an arbitrary amino acid sequence through matching to each position the value of the weight function of the region starting from this position. Example of input.
|
{kind=link}